June 18, 2026
Culture
The Making of the [un]CFO: Building a Company in the Age of AI
Written by:
A number of people have asked me recently: What is an [un]CFO?
To be completely transparent, I never aspired to be a CFO. What has always driven me is solving hard problems and learning. That is why I studied engineering and, counterintuitively, became a banker after my MBA to learn from the best technology leaders in the world. And it is why, when I first spoke with Naveen Rao, it took me only two days to decide to join the Unconventional AI team in trying to tackle the biggest technology problem we face today. I told Naveen, “I want to help build this company! I know you need help with finance, and I’m happy to do that. But I want to do more.”
It is not that I can’t do the work. And it is not that accounting and finance are not interesting. I can, and they are. There are plenty of people much smarter than me who have dedicated their careers to excellence in these fields. But for me, it is very simple. That is not what drives me!
What drives me is a hard problem that keeps me up at night. The kind of problem I keep chipping away at in bed, on a walk, or in the middle of dinner. I love the intensity of a negotiation. The thrill of a deal. I like to think and tinker. I like to learn. And I like to solve problems.
So when it came time to finalize the offer, Naveen asked: “What should we call you?” I jokingly said, “Not the CFO.” He started laughing and said, “How about [un]CFO?” And it clicked. [un]CFO for [un]Conventional. So that is how we landed on the title, and the first [un]CFO was born.
That said, he immediately became the [un]CEO. Which, I guess, makes me the CFO after all.
Over the next few pages, I’m going to walk through what I’ve actually been doing in the past five months. It spans finance, research, recruiting, legal, partnerships, company building, and a lot of things that do not fit neatly into any one bucket. The thread that ties it all together is AI itself.
I have done a lot of interesting things throughout my career, from the IPOs of Facebook and Twitter, to selling WhatsApp and LinkedIn, and running a global investment team at Prosus. Spoiler alert: the past five months have been the most interesting of my career.
Finance: The Table Stakes
When I joined Unconventional in January 2026, the team was 14 people. We had payroll and expenses running, but that was about it: no accounting, no budgeting, no reporting. With a cap table that includes more than 70 investors and the amount of money we have raised, everything has to be buttoned up.
So, I started with the basics. I built a budget, stood up our accounting flows, set up our share management system, and put expense policies, POs, and other processes into place.
What came next was more interesting. Concurrently, I started working with Naveen on our investor strategy. We had just announced our raise, but the round hadn’t closed, and inbounds kept coming in. We created a targeted investor list, to complement our existing world-class VC investors, and over the following months had 100+ investor meetings and attended several conferences like Morgan Stanley TMT, UBS, Jefferies, and HumanX (see Figure 1).
 Figure 1. Investor meetings and conference appearances during the fundraising process.
Figure 1. Investor meetings and conference appearances during the fundraising process.
One thing I’ve learned from my years as a banker and investor: cold outreach around a transaction is generally bad form. The best practice, I always told my clients and followed myself as an investor, is to meet companies early, follow their story, and track credibility. What did they tell you they were going to do? What did they actually deliver the next time you saw them?
That’s what I set out to do here. Educate investors early, lay out our plans, and then show them what we delivered. Build the track record before you need the money. We also raised an additional $60 million as a bonus, bringing our total round to $535 million.
Research: Building [un]Intelligence
While getting finance stood up, I had to get smart on what we’re actually building. I’m probably the only person at Unconventional without a PhD, so I attended engineering meetings, read papers, and tried to get my head around our work.
That’s when I discovered a bottleneck. We’re a research-heavy company, still in the R part of R&D, and the team shares a high volume of academic papers over Slack. PDFs, links, X posts, direct links to paper websites, all scattered across channels. Keeping track of what’s important was nearly impossible.
So I built a tool (see Figure 2).
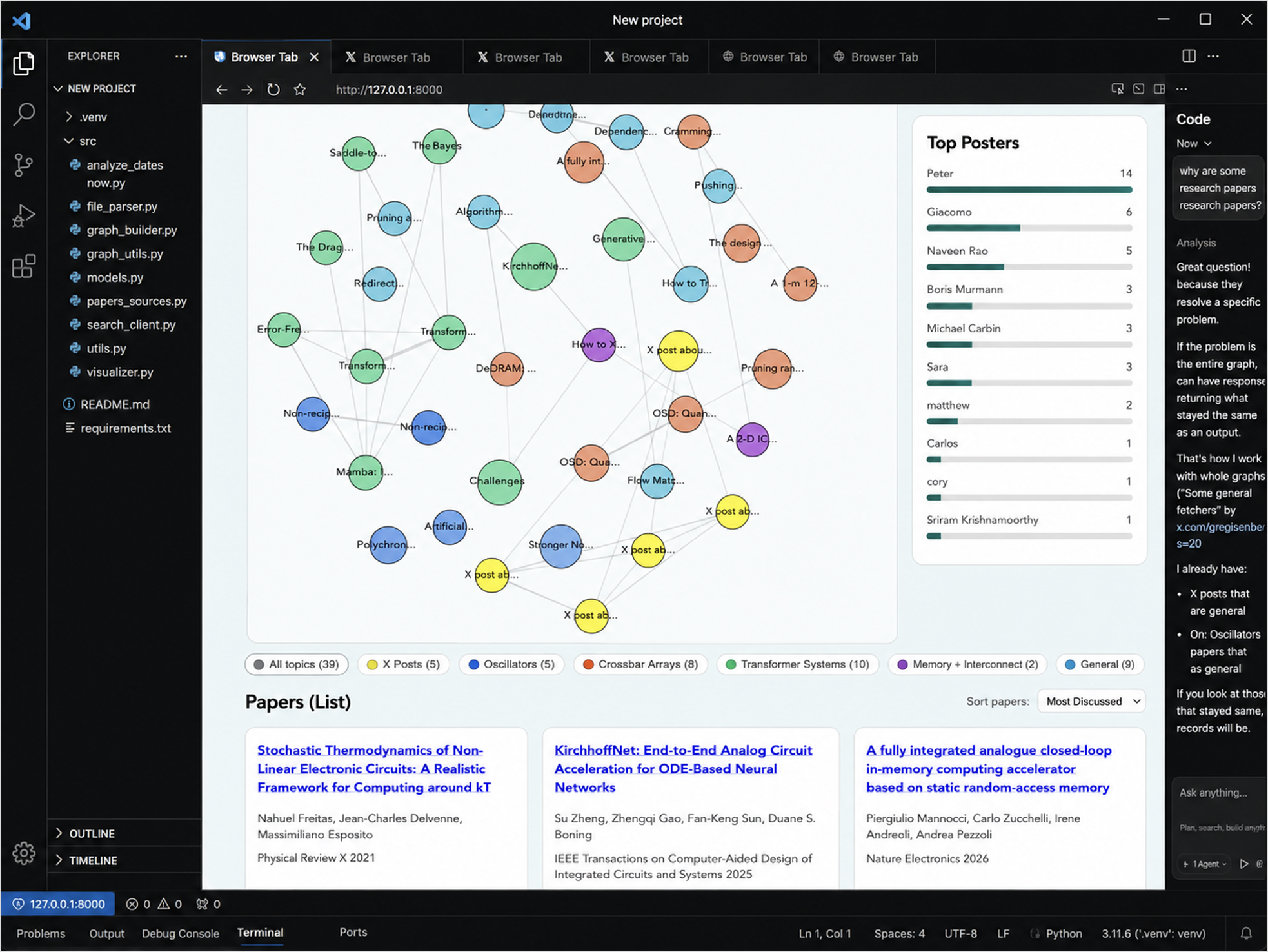 Figure 2. Version 1 of [un]Intelligence, showing the early paper-mapping interface.
Figure 2. Version 1 of [un]Intelligence, showing the early paper-mapping interface.
I started coding on Cursor to create something mostly for me, a way to ingest all the papers coming in over Slack, categorize them, summarize them, and visually map how they relate to each other. I had not coded for more than 20 years, so it took a couple of tries. But when I showed it to one of our researchers, Matthew Bull, he started asking, “Can it find this? Can it do that?” It worked. So I kept building.
The tool now runs on Databricks and has grown to roughly 100,000 lines of code. The ingestion pipeline pulls from Slack, Zotero, and manual uploads (see Figure 3). Parsing those sources is more complex than you’d think, since papers arrive as PDFs, links, posts, and everything in between. I’m using Docling for PDF-to-markdown conversion, optimized on GPU clusters (A10s for smaller batches, H100s for larger runs), with everything chunked and stored in a Databricks vector database.
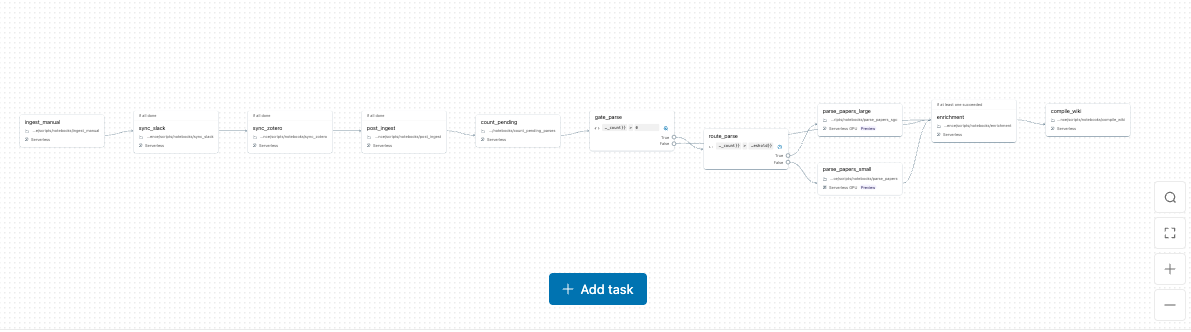 Figure 3. The ingestion pipeline for Slack, Zotero, and manual uploads.
Figure 3. The ingestion pipeline for Slack, Zotero, and manual uploads.
Each paper gets a wiki page (see Figure 4): abstract, synthesis, Slack discussion summary, the full text, the PDF, and links back to the original Slack conversation. Users can explore relationships between papers, click on a concept, and see every related paper. I took some visual inspiration from Obsidian for the concept graph (see Figure 5).
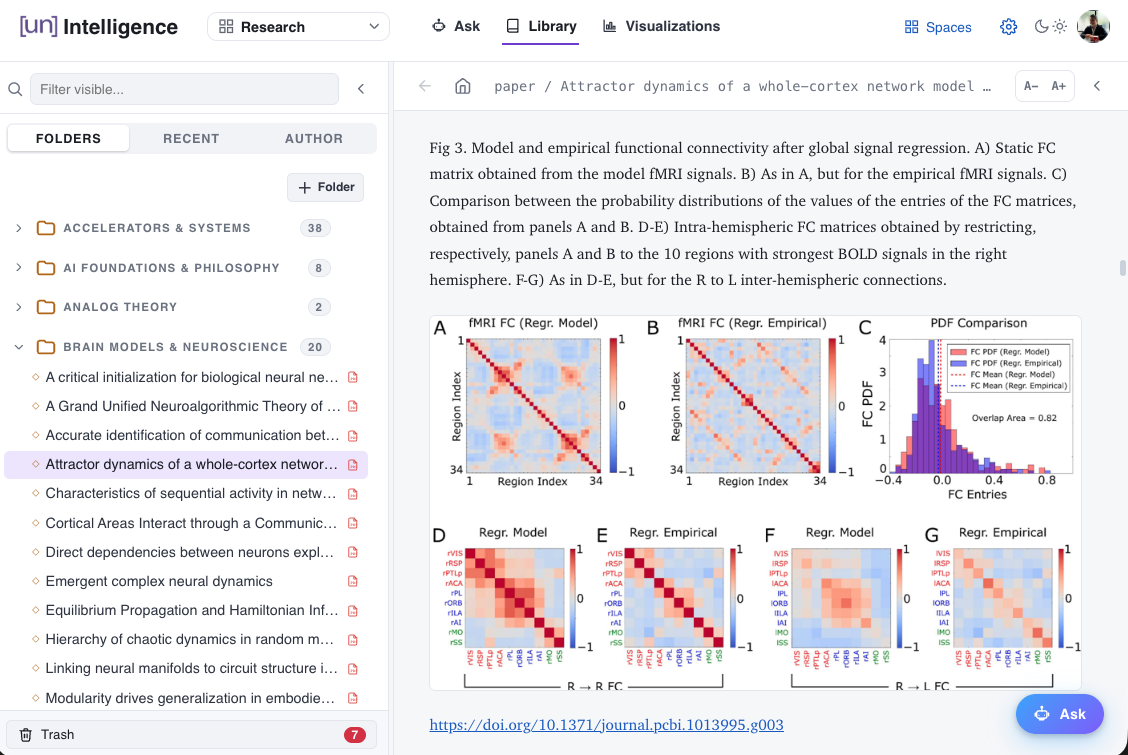 Figure 4. The paper wiki view, with abstract, synthesis, Slack discussion summary, and related links.
Figure 4. The paper wiki view, with abstract, synthesis, Slack discussion summary, and related links.
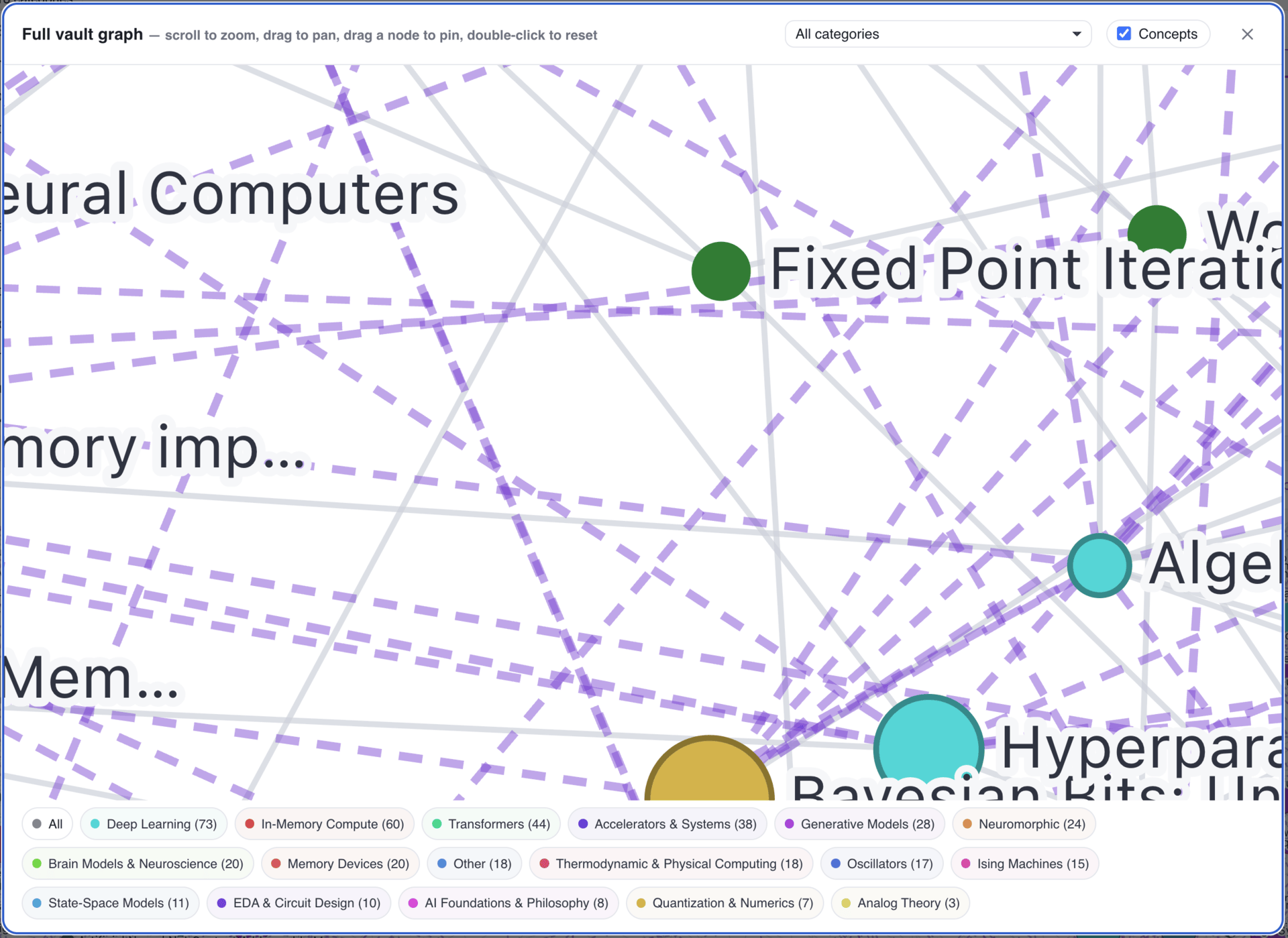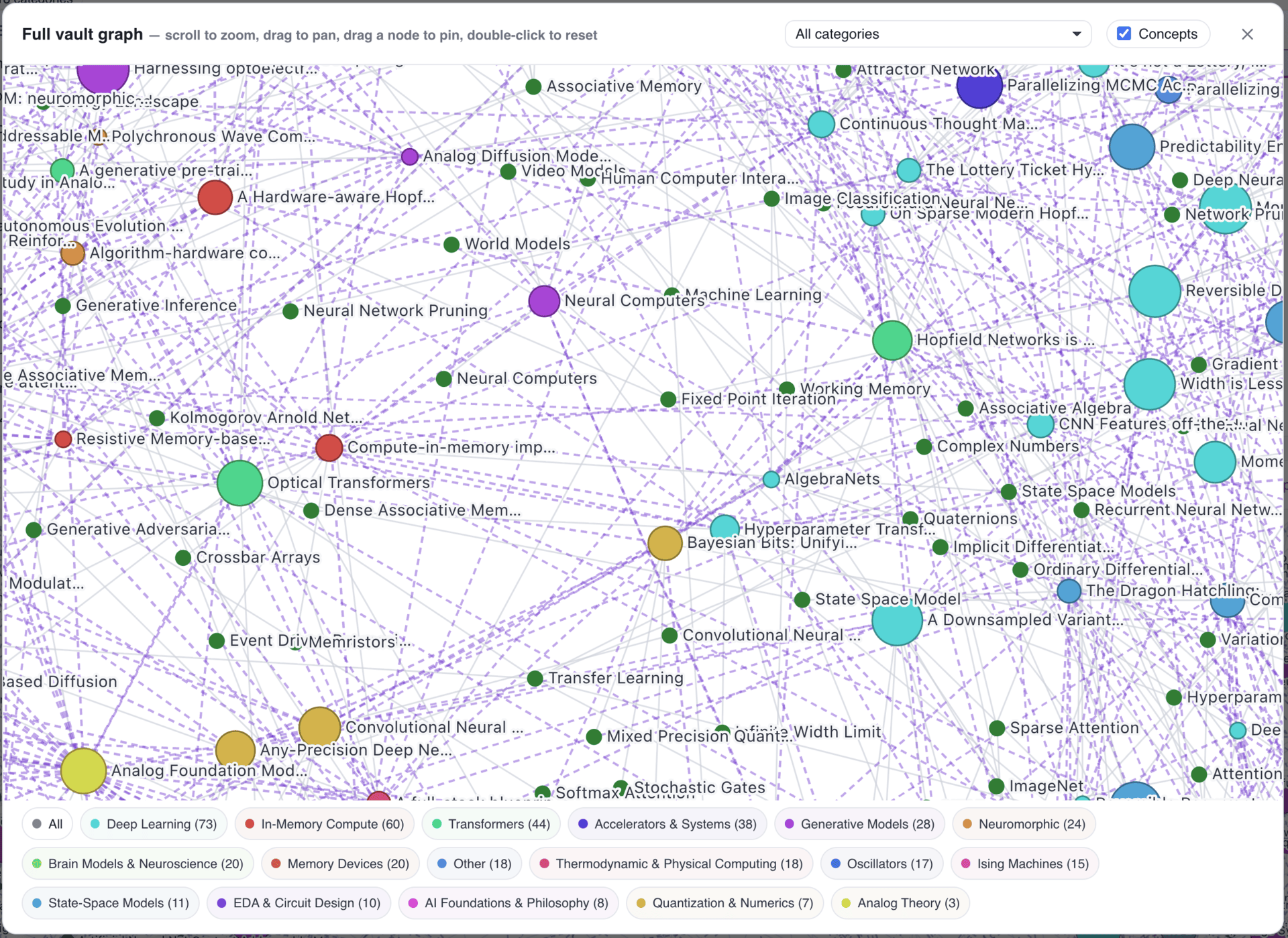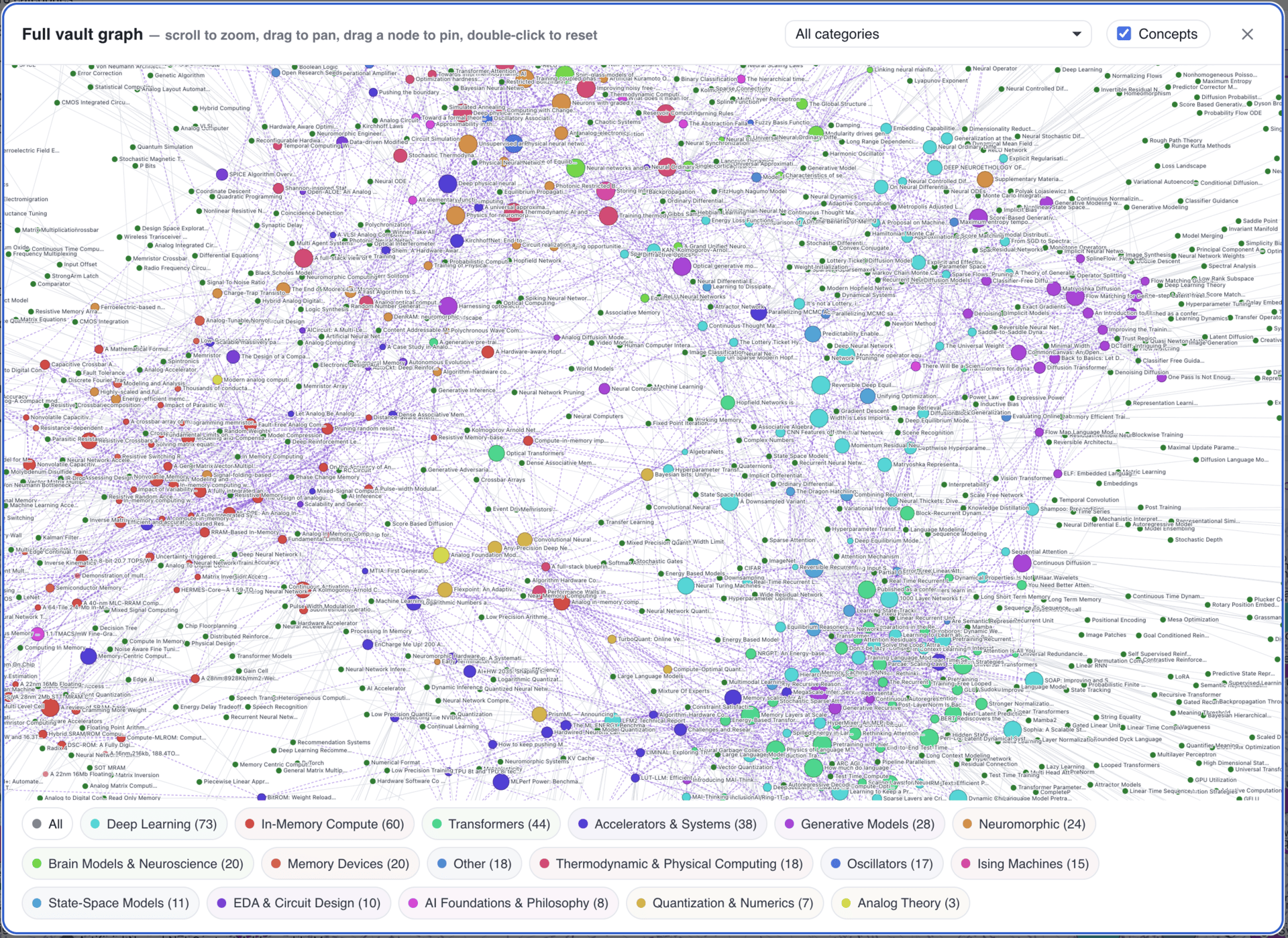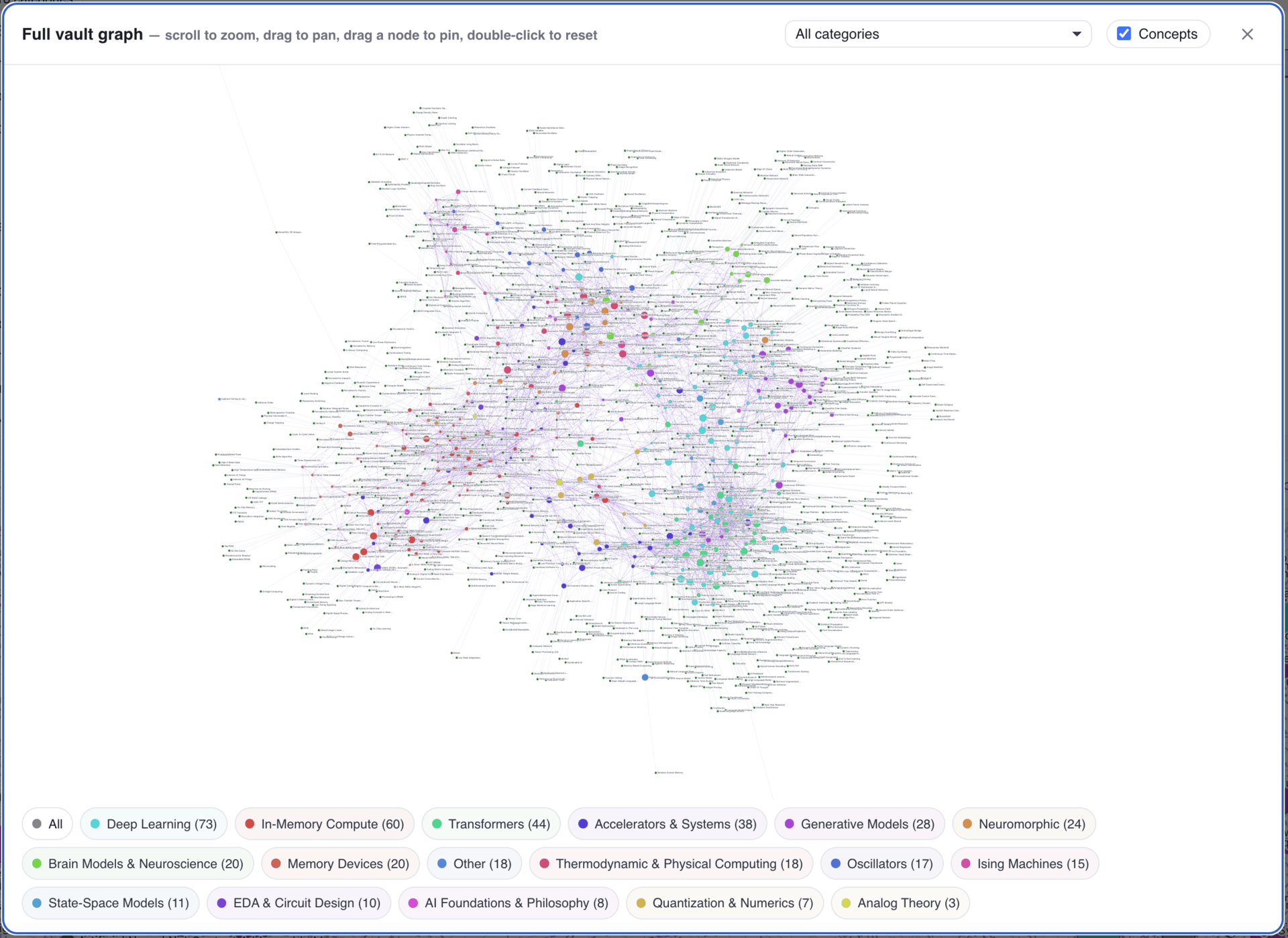 Figure 5. Concept graph showing relationships across the research library.
Figure 5. Concept graph showing relationships across the research library.
On top of the library, I built an AI agent with contextual search (see Figures 6 and 7). It can answer complex questions about what’s in the library, relate concepts across papers, surface ideas, and check them against Slack conversations. Over the following weeks, I integrated the agent back into Slack, so engineers can query the library without leaving the environment they’re already working in.
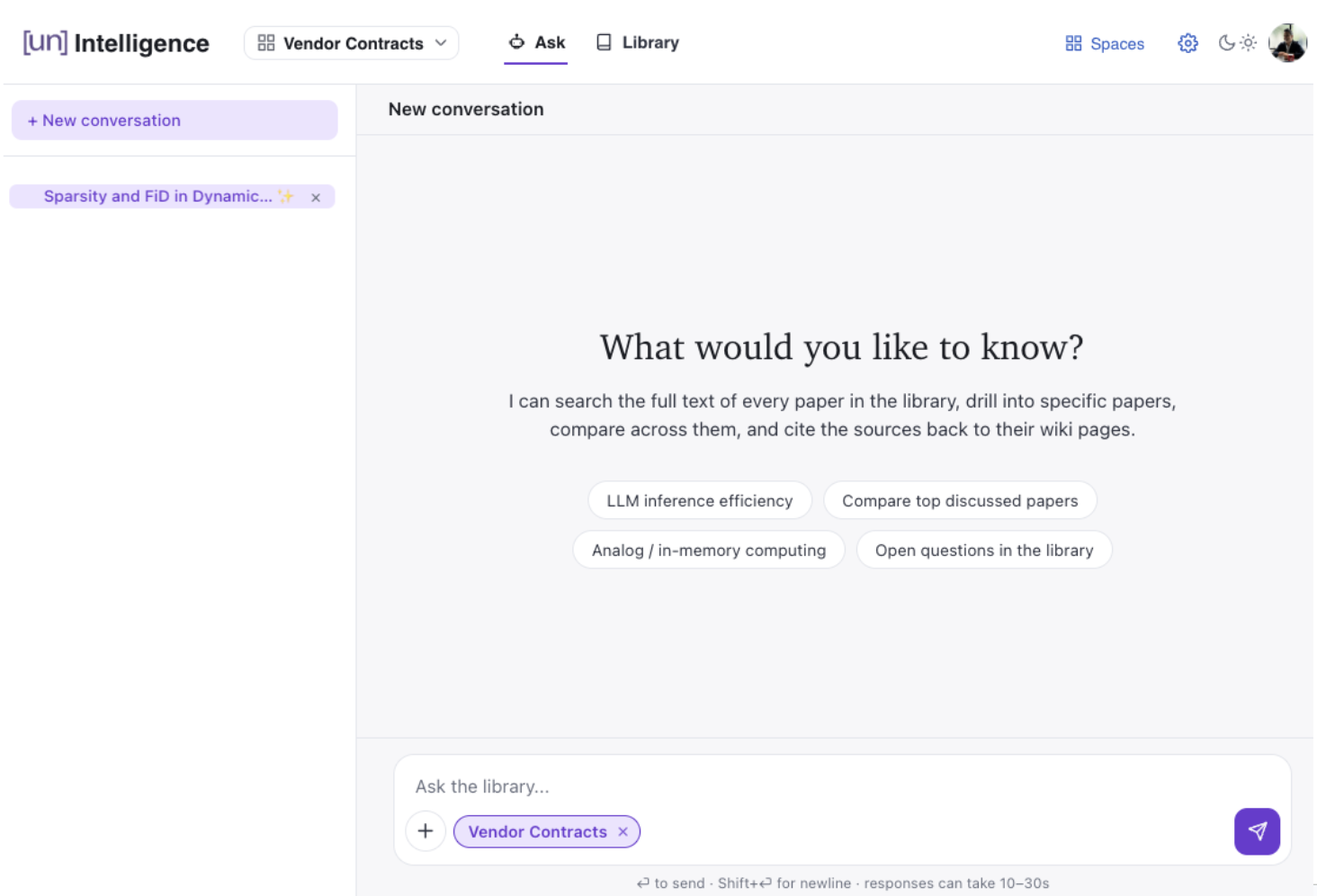 Figure 6. The [un]Intelligence agent interface.
Figure 6. The [un]Intelligence agent interface.
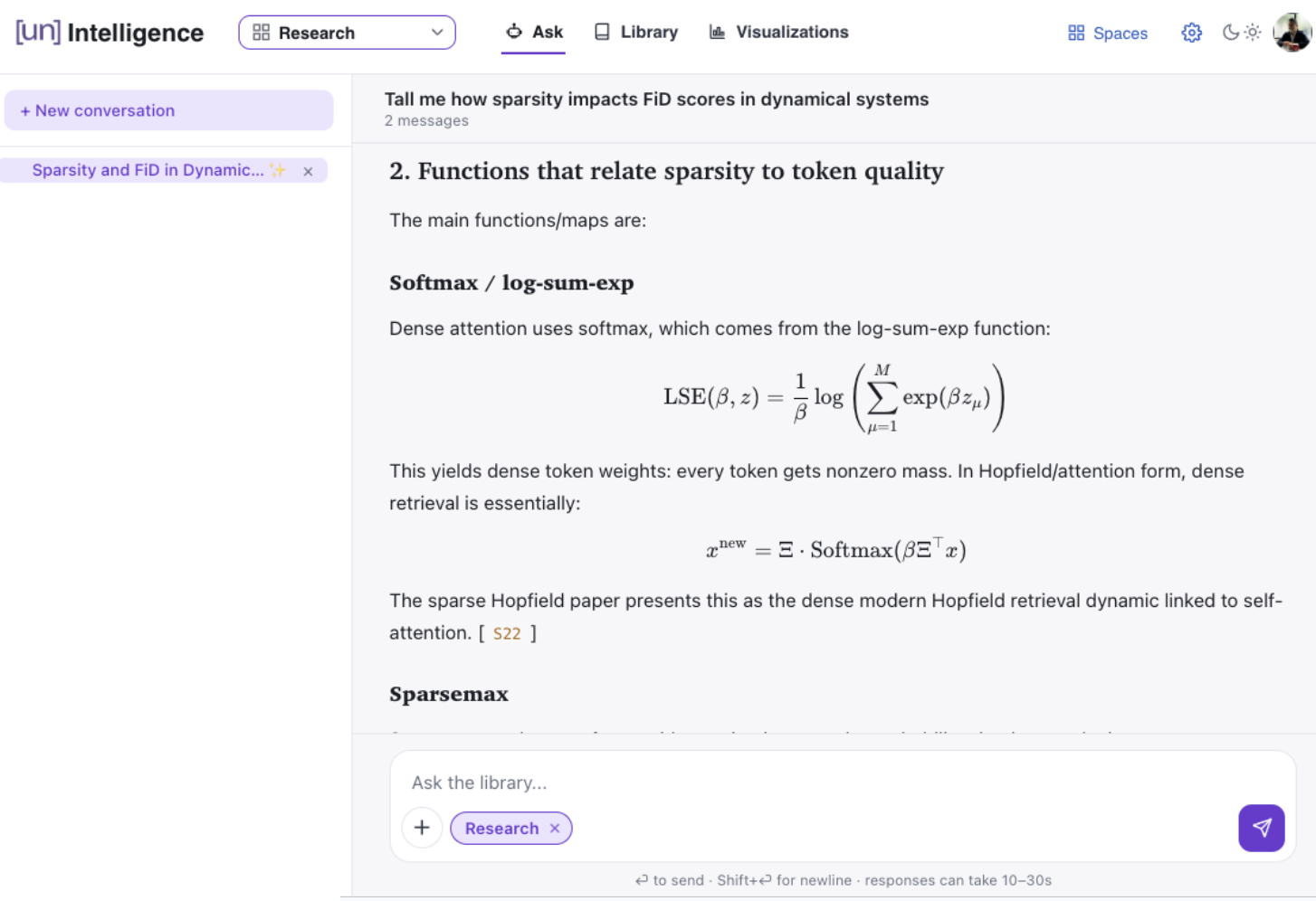 Figure 7. The AI agent answering a technical question using context from the research library.
Figure 7. The AI agent answering a technical question using context from the research library.
Then, a couple of weeks ago, one of our engineers, Pietro Caragiulo asked if we could load all 300+ EDA manuals into the tool so he could query them directly from Claude Code. So I built [un]Intelligence Spaces. Each space creates a new document class, connects to a source folder to ingest them, parses and embeds them in a vector database, and creates an MCP that users can use to access the knowledge inside their AI workflows. This is all automated and happens seamlessly in the background. Now we have spaces for various engineering manuals, legal docs, contracts, etc. (see Figure 8).
 Figure 8. Spaces workflows.
Figure 8. Spaces workflows.
The whole app, including ingestion pipelines, vector databases, the wiki compiler, agents, MCPs, and the front end, runs entirely on Databricks. Authentication, GPU compute, model endpoints, and three different database types are all under one roof. No other vendors needed.
For a company doing the kind of research we’re doing, this has been a real force multiplier.
HR: Building [un]Qualified
Given the profile of Unconventional and our founding team, we receive a lot of applications. A lot. And with a small team laser-focused on reinventing the entire AI stack, we can’t afford to waste cycles interviewing candidates who aren’t promising or, worse, miss the ones who are.
Our recruiting team is very capable, but the sheer volume is overwhelming. Good candidates were getting lost in the pipeline. So I offered to build something.
Using the Greenhouse API, I built an MVP in about 48 hours. The idea was simple: pull all applications, analyze each candidate, and evaluate how well they match the role. The early results looked promising, so I sat down with our head of recruiting, Shawn Flood, refined the flows, and built the full tool on Databricks (see Figure 9).
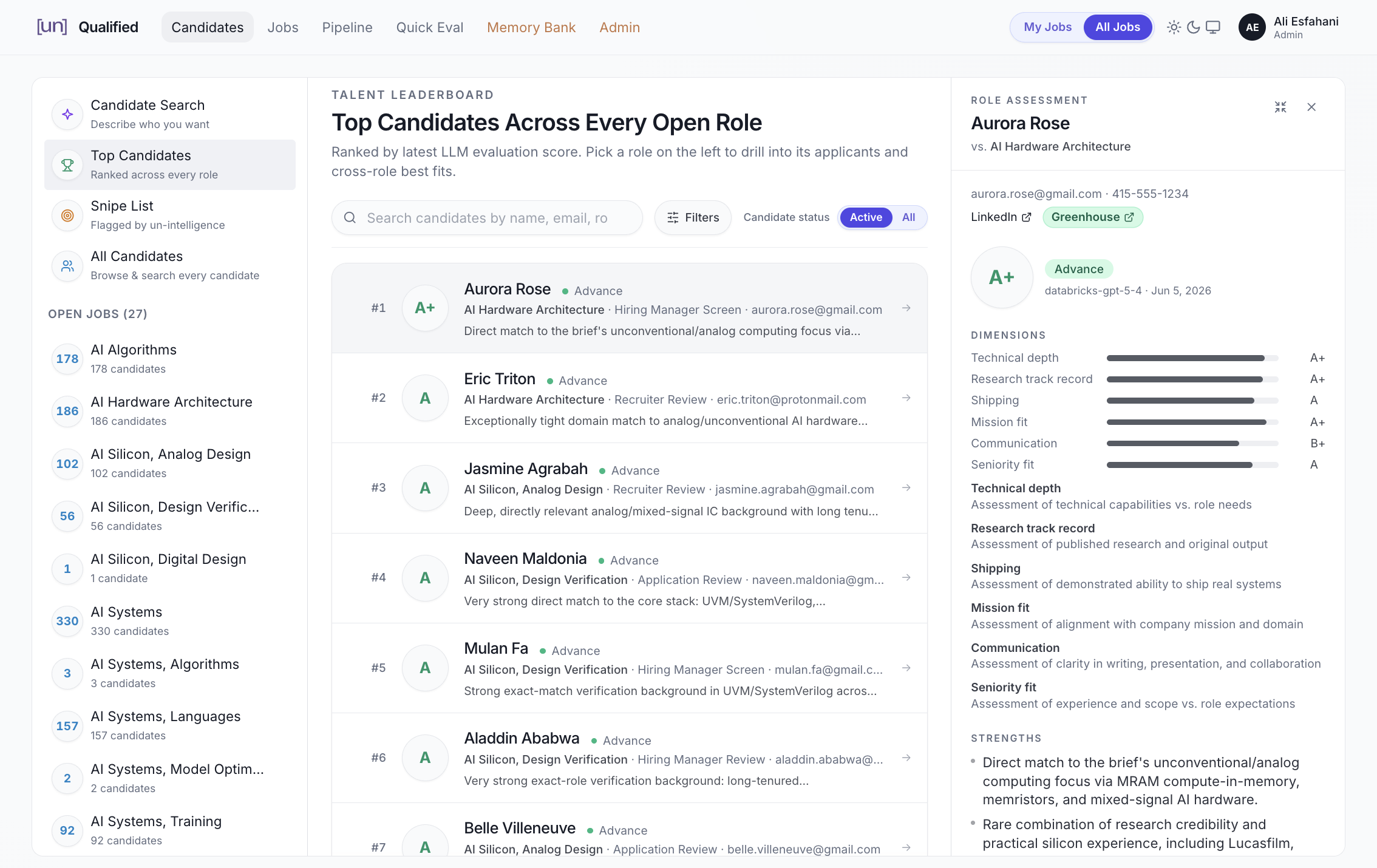 Figure 9. [un]Qualified candidate dashboard, showing role-by-role rankings.
Figure 9. [un]Qualified candidate dashboard, showing role-by-role rankings.
Here’s how it works (see Figure 10). For each candidate, the system builds a comprehensive dossier that includes not just the resume, but also any links it contains, the cover letter, LinkedIn profile, and publications on Semantic Scholar or Google Scholar. A true 360-degree view from everything publicly available that the candidate pointed us to.
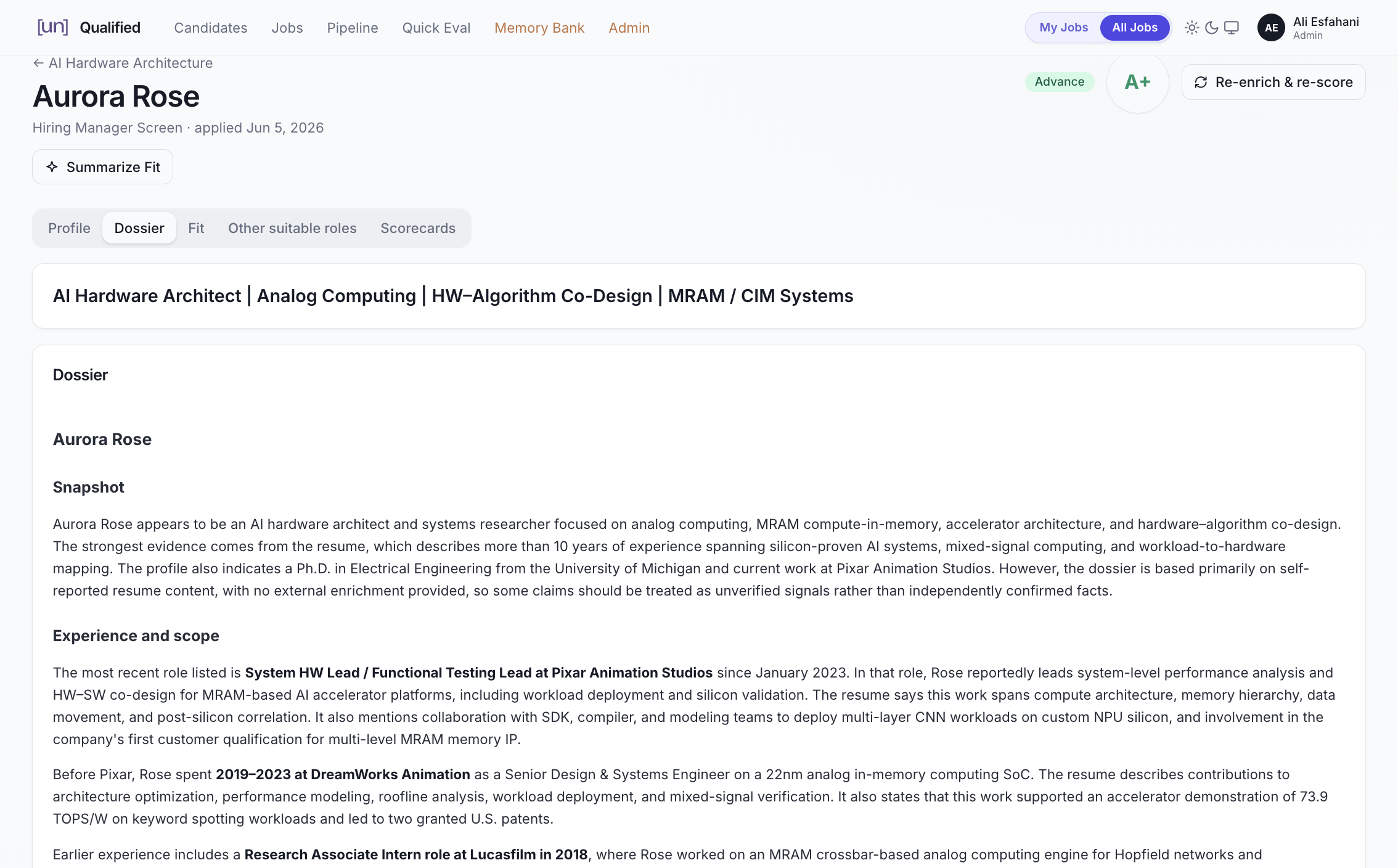 Figure 10. Candidate dossier view, including a snapshot and technical profile.
Figure 10. Candidate dossier view, including a snapshot and technical profile.
Then it evaluates that dossier against three inputs: the job description, the company mission, and as the key addition, the hiring manager’s description of their ideal candidate. That internal view is critical, because the public job posting is intentionally broad. The hiring manager’s lens fine-tunes the evaluation significantly (see Figure 11).
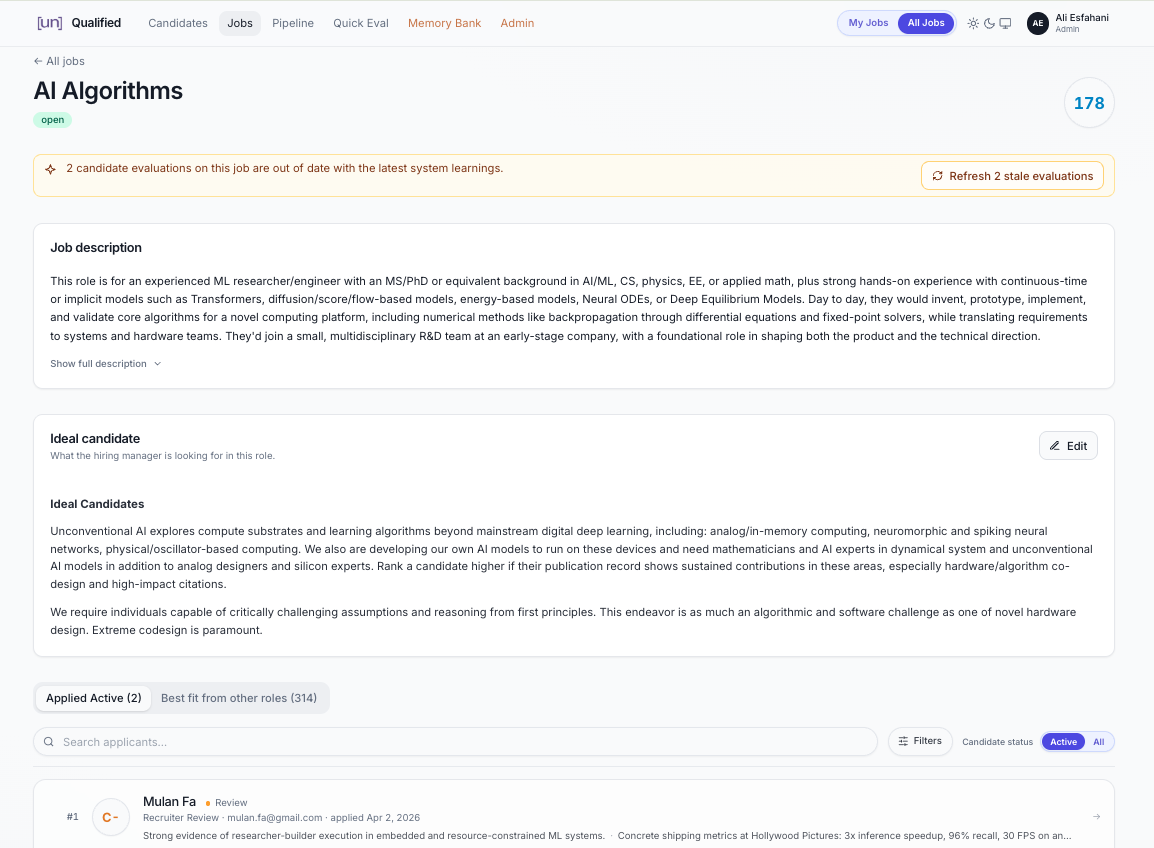 Figure 11. Role view, including the job description, ideal-candidate criteria, and ranked applicants.
Figure 11. Role view, including the job description, ideal-candidate criteria, and ranked applicants.
The system reviews each candidate across six dimensions, weighted by relevance to the specific role. But it does more than that: it evaluates every candidate against all open positions across the company. So, if someone isn’t right for the role they applied to, but would be a strong fit for another team, that gets surfaced (see Figure 12). To be clear, we are not stack-ranking candidates; we are just trying to surface good fits so we can review them more comprehensively (human judgment is still key).
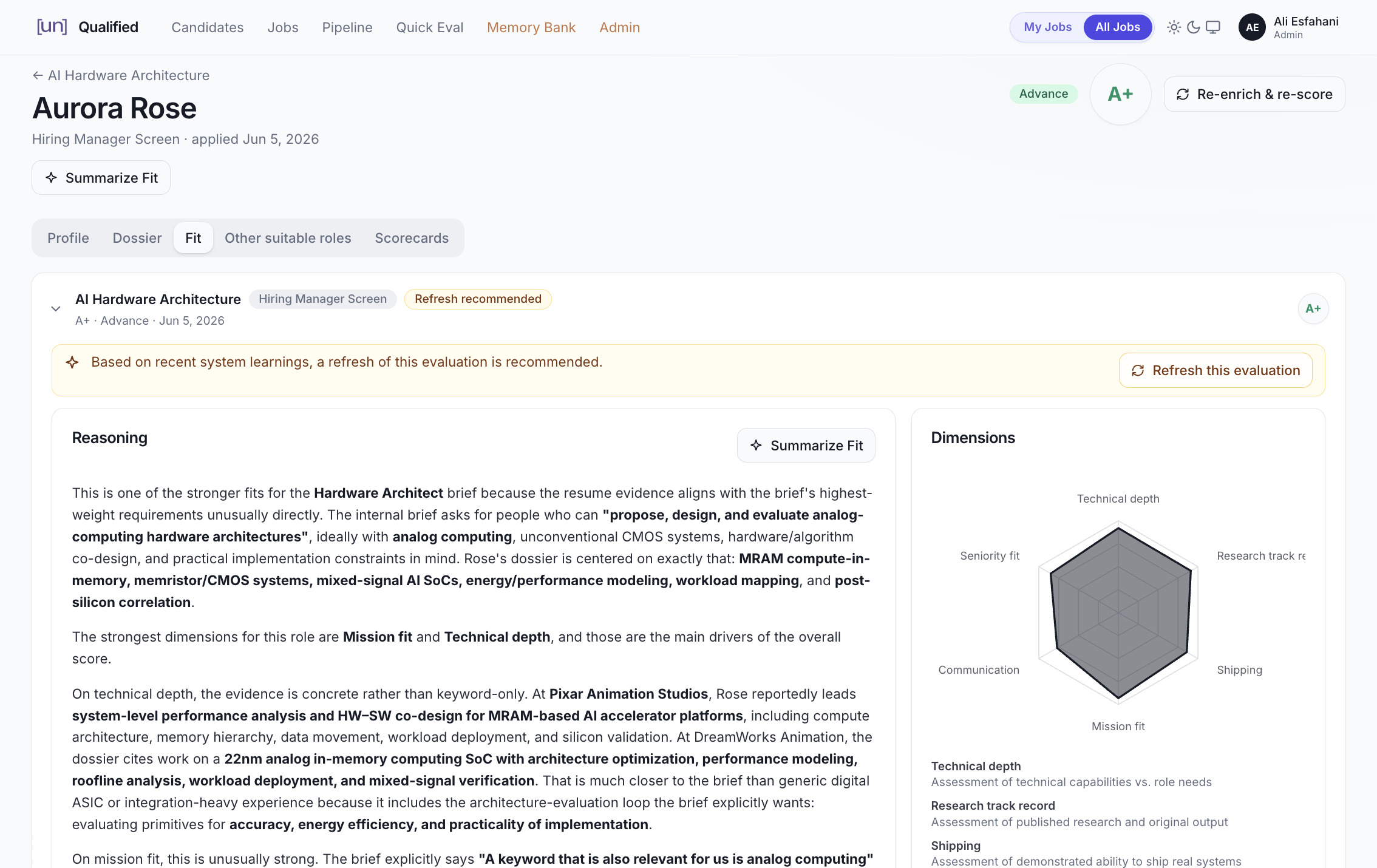 Figure 12. Candidate evaluation view, showing reasoning and dimension-level scoring.
Figure 12. Candidate evaluation view, showing reasoning and dimension-level scoring.
And here’s where things get interesting: the paper library and the recruiting tool talk to each other. Many of the papers we’re reading are authored by PhD students and researchers at places like Stanford and MIT doing work that’s directly relevant to what we’re building. In one instance, an incredible applicant went unnoticed for three months simply because we struggled to filter the exceptional talent from the noise. Today, when one of those authors appears in our candidate pipeline, the system flags them immediately, and we expedite their application.
That kind of cross-functional intelligence wasn’t possible before. When you surface the right data and connect the dots, you can move faster and make better decisions.
[un]Qualified was working great, but I decided to go one step further. After each interview, our team leaves notes in Greenhouse about the candidate. We compare these human judgments against the LLM’s pre-interview evaluation and, over time, train the system to do a better job of identifying traits that we were not able to verbalize upfront. By closing the feedback loop, the system is getting better at identifying the things that actually matter for our specific team, not just what looks good on paper.
Legal: I Hired Claude as Our First Legal Employee
We’re still early, so we still don’t have a general counsel. We will eventually hire someone, but today we have to keep our eyes on more pressing matters. But contracts don’t stop coming just because you’re a startup.
Thanks to George Boutros and Jonathan Turner at Qatalyst Partners, I’ve reviewed enough contracts throughout my career to play a lawyer in a B-rated movie. But with my time split across finance, building tools, investor relations, and everything else, I can’t spend hours reading 100-page vendor agreements or negotiating the handful of NDAs we process every week.
So I hired my first legal employee: Claude.
I’m using Anthropic’s Cowork 3P platform with its legal plugin, and it has been genuinely effective. I’ve fed it our form NDA and standard contract terms, told it which issues matter to us, and now, when a contract comes in, it reviews it against our forms, flags deviations, creates issue lists, and generates markups with my input.
I review everything, give it feedback, and iterate. What used to take hours now takes minutes!
So, What Is an [un]CFO?
Over the past five months, I’ve been head of finance and accounting. I’ve been our investor relations lead. I’ve written roughly 200,000 lines of code across three internal AI tools (yes, there is a third one in the works). I’ve been our pseudo-general counsel, with an AI legal assistant. And I’ve been trying to learn as much as I can about unconventional computing from a team of PhDs who are far smarter than I am.
If I had to summarize the job in one sentence, it is this: using every AI tool available, including building new ones, to help an exceptional team move faster on a mission that will change the world. I can do it because we are building an unconventional company to do unconventional things, and we are defining how a company should be built in the age of AI.
The thread connecting all of this is AI. Not AI as a product we sell, but AI as the way we operate. Every function I’ve touched, including finance, research, recruiting, and legal, has been augmented or rebuilt around intelligent systems. Not because it’s trendy, but because when you’re a small team trying to do something that normally requires hundreds of people, you don’t have a choice. You have to find leverage wherever it exists.
I still don’t know what the right title for this job is. But I think [un]CFO fits pretty well.
If you’re interested in doing unconventional things, come join us at Unconventional AI. We’d love to hear from you.