April 30, 2026
Research
Analog is dead, long live analog!
Written by:
Today’s electronic systems thrive on digital information processing, invoking analog circuits mainly to condition and digitize physical signals. The digital abstraction, which largely ignores analog nuances and promotes bits as the fundamental carriers of information, has been instrumental in managing complexity and pushing transistor counts well past 100 billion per chip.
In the context of today’s AI systems, the success of digital hardware and the many abstraction layers that we’ve built on top are a mixed blessing. We all agree that digital systems have paved the road toward modern AI, but what can we do to address the pressing need for order-of-magnitude increases in energy efficiency? Will relaxing the digital abstraction and computing by analog means save the day?
Questioning digital is trendy, but not new
In his 1990 paper, Eric Vittoz discussed the “Future of analog in the VLSI environment” and investigated the efficiency of analog versus digital signal processing. His conclusion was that analog circuits will remain advantageous for low-precision applications such as neural networks. About 30 years later, I took a fresh look at this analysis using updated technology parameters and focusing on dot products, the workhorse of modern AI/ML. A graphical summary of this study (see IEEE TVLSI, Jan. 2021) is shown below.
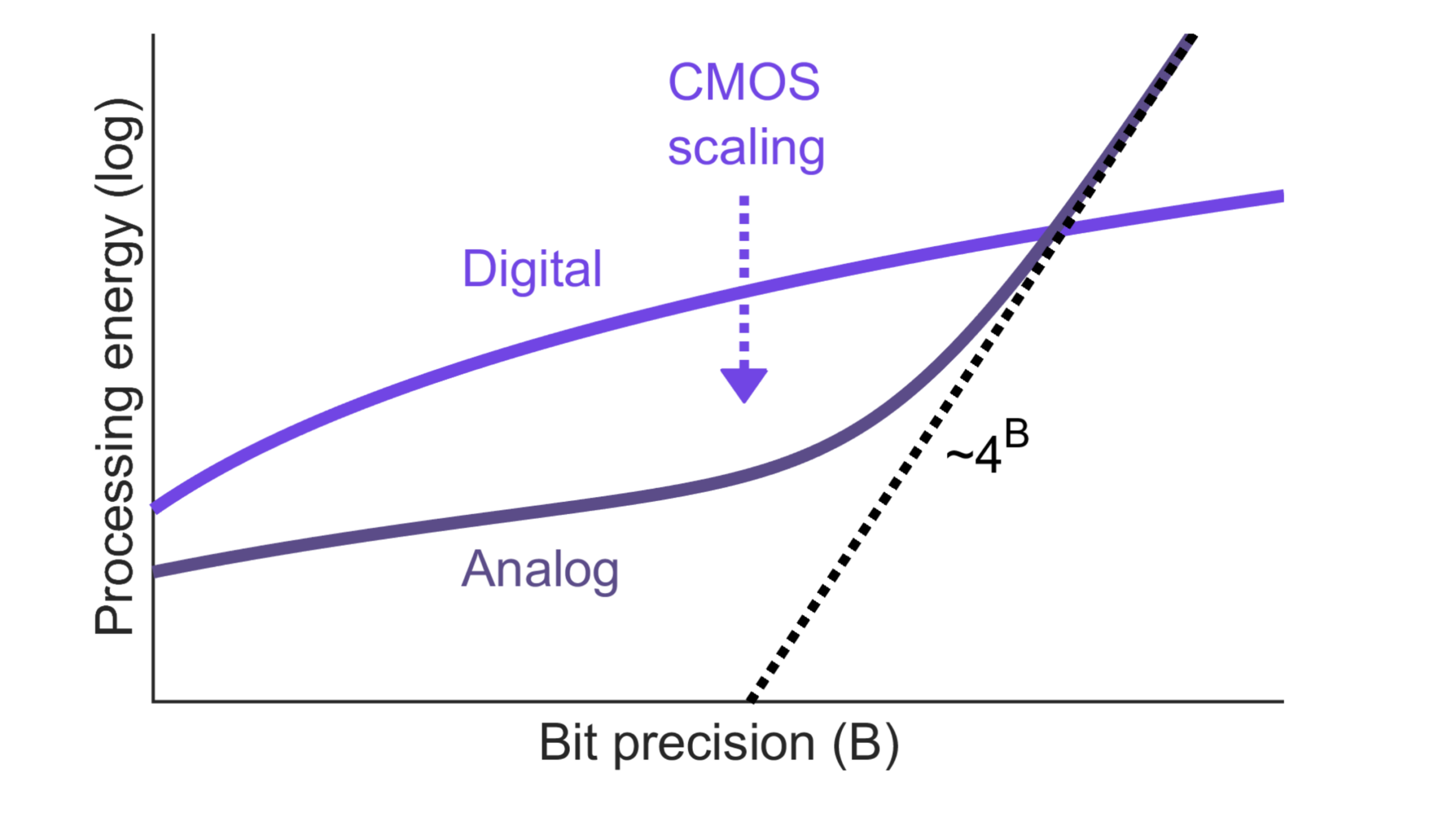
For dot products with high-bitwidth operands (>8 bits or so), the analog energy cost rises steeply since thermal noise becomes the dominant non-ideality. Since the rms value of thermal noise is proportional to √(kT/C), achieving an extra bit of precision quadruples the required capacitance, hence quadrupling the energy. In the low-precision regime of 1-4 bits, analog dot products can be more efficient than digital ones due to their structural simplicity. For example, a data-weighted charge-sharing circuit using tiny capacitors may use less energy than a “bulky” multiply-add in digital logic.
How big is the analog advantage? In the latest FinFET nodes, 4-bit MAC operations in a digital in-memory compute column can achieve >100 TOPS/W (10 fJ/op). The best analog implementations to date boast several hundred TOPS/W. So, unfortunately, the gap between analog and digital for dot product computations is not as large as we would like it to be.
Part of the problem is that we don’t have “good” analog memory, and therefore need A/D and D/A interfaces to digital memory. Vittoz wrote in 1990: “The important problem of storing analog values is being attacked in various ways and will no doubt find solutions sufficiently dense to build large learning systems.” That solution is still a work in progress, 35+ years later.
Don’t trust TOPS/W numbers you haven’t doctored yourself
It is tempting to get in the weeds on TOPS/W benchmarking. However, the TOPS/W of a compute array depends on countless factors (sparsity, throughput, latency, area density, noise, robustness, etc.), making an apples-to-apples comparison nearly impossible. More importantly, we don’t really care about the TOPS/W (or its reciprocal, fJ/op) of a compute block at the AI/ML system level. A more interesting metric is the total energy per inference (or token). We can unpack this metric as shown below.

Through this equation, we can identify several scenarios in which a compute array with record-breaking fJ/op may not benefit the system. If the design comes with significant analog noise, a larger model may be required for iso-accuracy. This increases Ops/Inference and likely the energy cost of memory accesses (more memory accesses per operation and/or higher access energy for larger memories). Another aspect is the array’s write energy. Large analog arrays tend to do well in amortizing overhead for data conversion, which boosts their TOPS/W, but can also raise the equation’s memory energy term (if re-writes are required).
Clearly, designing an efficient AI/ML inference system isn’t merely about chasing high TOPS/W for a building block, but must focus on judicious co-design of the complete solution. This is typically achieved using a design space exploration that finds a Pareto front where the available “Legos” (digital or analog) are sized and utilized to balance the tradeoffs.
System size and specialization play a big role here. Small and well-defined workloads can be optimized to a higher degree. For the design of a “tinyML” processor for on-device classification tasks, my students found that interspersing small, hand-crafted memory arrays with nearby bit-serial digital computing synergizes best with the loop unrolling options for highly compressed ConvNets (see Doshi, 2024 VLSI Circuit Symposium). The lowest energy point for this processor was not achieved by optimizing the TOPS/W of its compute elements, but by searching for the best tradeoff between compute and data movement costs.
In the world of large-scale AI, this is easier said than done. Systems performing inference using hundreds of billions of model parameters are typically held hostage by DRAM. When half of your system energy is spent on external DRAM accesses during LLM decode, large efficiency improvements are hard to come by. System designers have been looking for ways to increase arithmetic intensity (number of arithmetic operations per memory access), but the benefits from batching and related tricks appear to be limited, and are unlikely to move the needle by orders of magnitude.
We need [un]conventional breakthroughs
It’s time to pay down the structural debt of our AI compute platforms. Today’s solutions clearly benefit, but are at the same time held back, by many decades of evolutionary progress in computing technology. What would happen if we collected the cans that have been kicked down the road and restarted with a clean slate? No one has a clear answer to this question, but there are many exciting directions that we can explore. Here is a small subset.
- Leverage the third dimension. It is great to stack DRAM on top of your CMOS compute chip, but there is likely more to be had. We need new ideas that help us overcome the curse of long wires.
- Embrace neural co-evolution. Achieving the best efficiency for AI computing will likely require a full stack optimization framework. AI model development should be energy aware. Hardware capabilities should inform model design (and vice versa).
- Look for alternatives to linear algebra. The expressivity and information density of high dimensional vector spaces are truly mind-boggling. Are there more compute- and memory-friendly (digital or analog) ways of encoding features, context, and similarity? For example, can we replace digital memory with implicit state retention via continuous dynamical systems?
Is analog dead?
Engineering is scientific design under constraint. In today’s deterministic, tera-scale, two-dimensional, vanilla-CMOS linear algebra engines, our structurally indebted constraint space does not favor analog processing.
Analog is dead.
For a clean-slate approach that promotes radically new directions, the answer is anything but obvious. I can imagine a world where analog and digital building blocks compute in unison, enhancing their strengths and mitigating their weaknesses in a new type of fabric. This mixed-signal system may overcome analog error accumulation using strong nonlinearities and leverage new semiconductor technologies for acceptable analog memory. Let’s be [un]conventional in this brave new world of opportunity.
Long live analog!