April 2, 2026
Research
Neural co-evolution, the inevitability of hardware and software co-evolution for AI
Written by:
The hardware and software silos
For the last 60 years or so, hardware and software have been largely considered separate disciplines. The application stacks began to grow complex, and software engineering became centered around managing complexity, interoperability, and extensibility. Without these practices, large-scale systems could never be designed to be reliable. Hardware, on the other hand, was generally designed for performance and flexibility, as the potential number of applications could be vast. In fact, the more generally applicable a piece of hardware is, the more valuable it could be. The discipline of hardware engineering was about delivering a clear abstraction on which software could be built.
Enter AI. These abstractions are less relevant and need to be rethought. Even within the field of software engineering, AI is changing the way we think of abstractions. Old abstractions have less value, as complexity management can be done by AI to deliver code specifically built for the application. Why doesn’t this apply to the hardware abstraction itself? The purpose of a computer has now shifted from a machine doing precise calculations for many applications to something that is the physical substrate for intelligence. Can we rethink this hardware/software boundary to build something better?
AI is a cargo cult of hardware primitives
The modern concept of a “neural network” goes back to the early 1940s, when physiologists McCulloch and Pitts introduced the first mathematical model of a biological neuron, demonstrating how a network of such neurons could perform logical functions. It was understood that each neuron exerted some influence upon the next. These biological systems were simplified to mathematical models and eventually simulated on a computing machine. Over the subsequent decades, Hebbian learning, backpropagation, and other learning methods were refined to train artificial neural networks to do useful tasks. The field of artificial neural networks began to emerge as a method to build learning systems.
In the mid-2000s Nvidia introduced the concept of the General Purpose GPU (GPGPU) and CUDA. GPUs steadily made inroads into the High Performance Computing (HPC) segment, driving greater computing density and faster memory access. At the same time, neural networks, which had now become known as deep learning, increased in complexity and grew in dataset sizes requiring greater computational power beyond single CPU systems. This culminated with the AlexNet moment in 2012, when deep learning demonstrated strong performance in image recognition against alternative techniques. In the hunt for even greater scale, Jeff Dean and others at Google made the decision to rewrite DistBelief (one of the first large-scale neural network training frameworks) from CPUs to GPUs and ordered 40,000 Nvidia GPUs. These shifts enabled large neural networks to be trained on vast datasets in practical timescales. Neural networks began to be designed around computing primitives well-suited to GPUs, namely, matrix multiplication and vector operations.
This historical compromise has led us to what is now a profound disconnect: the abstractions, or symbols, lost their original meaning. Similar to the famous Cargo Cults of the Pacific Islands, who mimicked rituals associated with Western visitors without understanding the underlying function, neural network hardware primitives became dogma rather than purpose-driven design. Linear algebra, though a powerful tool for many problems, became the undisputed foundation. The fundamental question of whether linear algebra truly represents the most efficient way to express neural network activity was sidelined in the push for faster, larger models with more data.
As the hardware industry is accustomed to building to a well-defined abstraction, this has created a significant innovation logjam in the AI hardware industry. On one side, the builders of neural networks assume only the existing computing primitives are available. On the other, hardware designers feel limited in their ability to modify the workload primitives.
At Unconventional AI, we don’t assume these physical efficiency limits of current hardware are a natural, unavoidable consequence of building intelligence. We are actively questioning these ingrained hardware primitives with the singular goal of developing AI systems that are vastly more power-efficient and powerful. The computer architecture pioneer John Hennessy advocates for vertical integration: “having Renaissance researchers who can actually communicate across [and] through that vertical stack to really do something interesting.” We want to go down a new path, a path that necessitates the co-evolution of the hardware and the neural network itself, a concept we term “neural co-evolution.”
Examples of co-evolution over the last decade
The industry has seen several notable attempts at co-evolution, each targeting specific systemic bottlenecks in the established GPU paradigm:
- Nervana: Nervana was an early mover, introducing an architecture in 2014 that focused on distributed matrix multiplication for neural networks. The importance of this specialization was validated when GPU manufacturers adopted this strategy in 2017. Nervana’s Engine optimized deep learning performance by pioneering the use of a low-precision and customized FlexPoint numerical format, which maximized performance for neural network operations.
- TPU (Tensor Processing Unit): Google’s TPU was a groundbreaking example of co-design, built specifically for serving smaller neural networks within Google’s infrastructure. Google recognized the value of optimizing hardware for their exact workload, which continues to be their primary approach. Technically, the TPU achieves its efficiency through massive, interconnected Matrix Multiplier Units (MXUs) that operate on a systolic array, coupled with high-speed High Bandwidth Memory (HBM) to reduce instruction overhead and maximize throughput in training and inference.
- Cerebras: Cerebras addressed the constraint of memory bandwidth, a major barrier to inference speed as networks scaled, by building at the wafer scale. This provided fast access to an enormous volume of on-chip memory (SRAM). The Cerebras Wafer-Scale Engine (WSE) integrates hundreds of thousands of cores and tens of gigabytes of on-chip memory onto a single piece of silicon, creating the world’s largest chip to date. This design effectively bypasses the conventional memory wall for specific workloads, though it is accompanied by a tax of high energy consumption and cost.
- Groq: Groq focused on an at-scale compute-near-memory architecture. Their core insight was recognizing that the cost and performance loss associated with off-chip DRAM might be a suboptimal trade-off. Their design allows the neural network to be distributed across multiple chips, each with fast, localized access to memory (SRAM). Groq achieves low-latency performance by implementing a deterministic, dataflow-like architecture, minimizing the non-deterministic overhead and control flow complexity that reduce efficiency in general-purpose processors.
- Hyperscalers (AWS Inferentia/Trainium): Cloud providers like AWS have built custom platforms, Inferentia (inference) and Trainium (training), that offer cost advantages over traditional GPUs. While public performance benchmarks are challenging to obtain, AWS has successfully positioned these chips for cost optimization within their specific cloud context. The second generation of Inferentia utilizes specialized NeuronCores and high-speed inter-chip interconnects to achieve optimal throughput and low latency for cloud-deployed models at a highly optimized cost point for their platform.
Initial results: Time as a first-class citizen
Our initial results center on using dynamical systems to seamlessly merge neural network requirements with novel hardware primitives.
Currently, digital computers must explicitly simulate dynamics using discrete reads and writes of state. We propose a different approach: harnessing the inherent physical dynamics that many electronic circuits already exhibit. The goal is to make the computation of state and next-state implicit, framing the problem as a true dynamical system. By treating Time as a first-class citizen in computation, we can unlock the potential for dramatic gains in power efficiency.
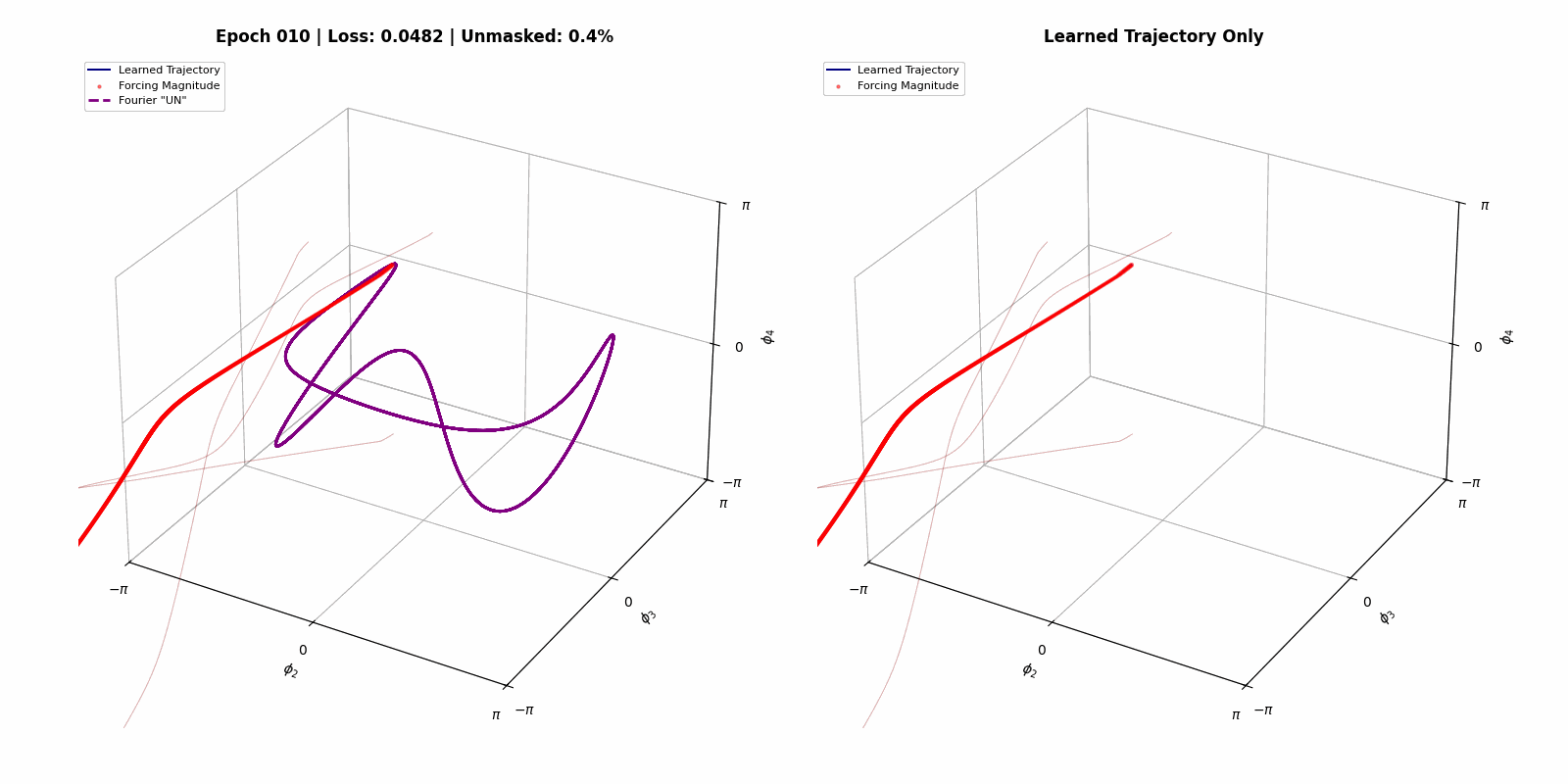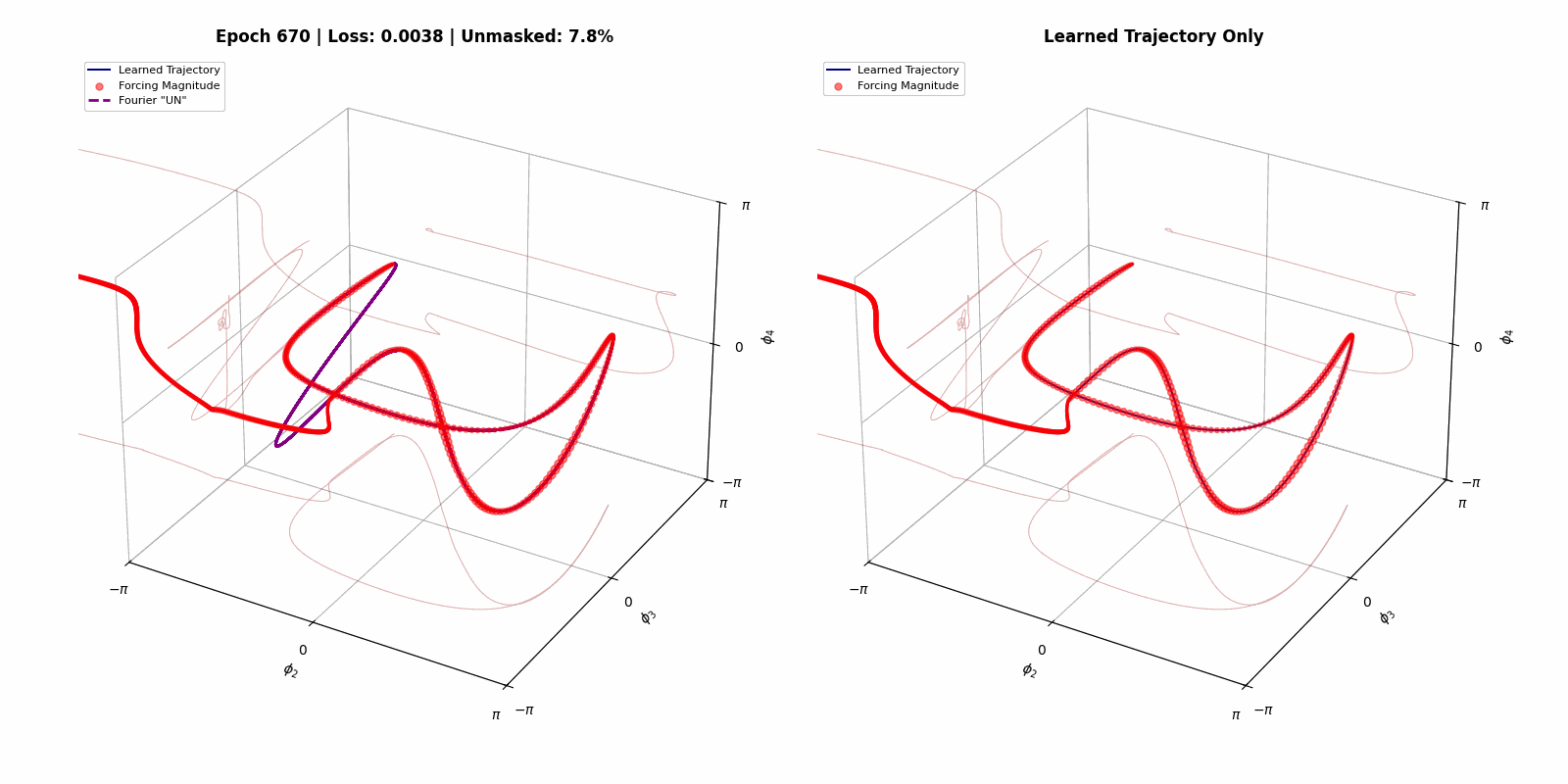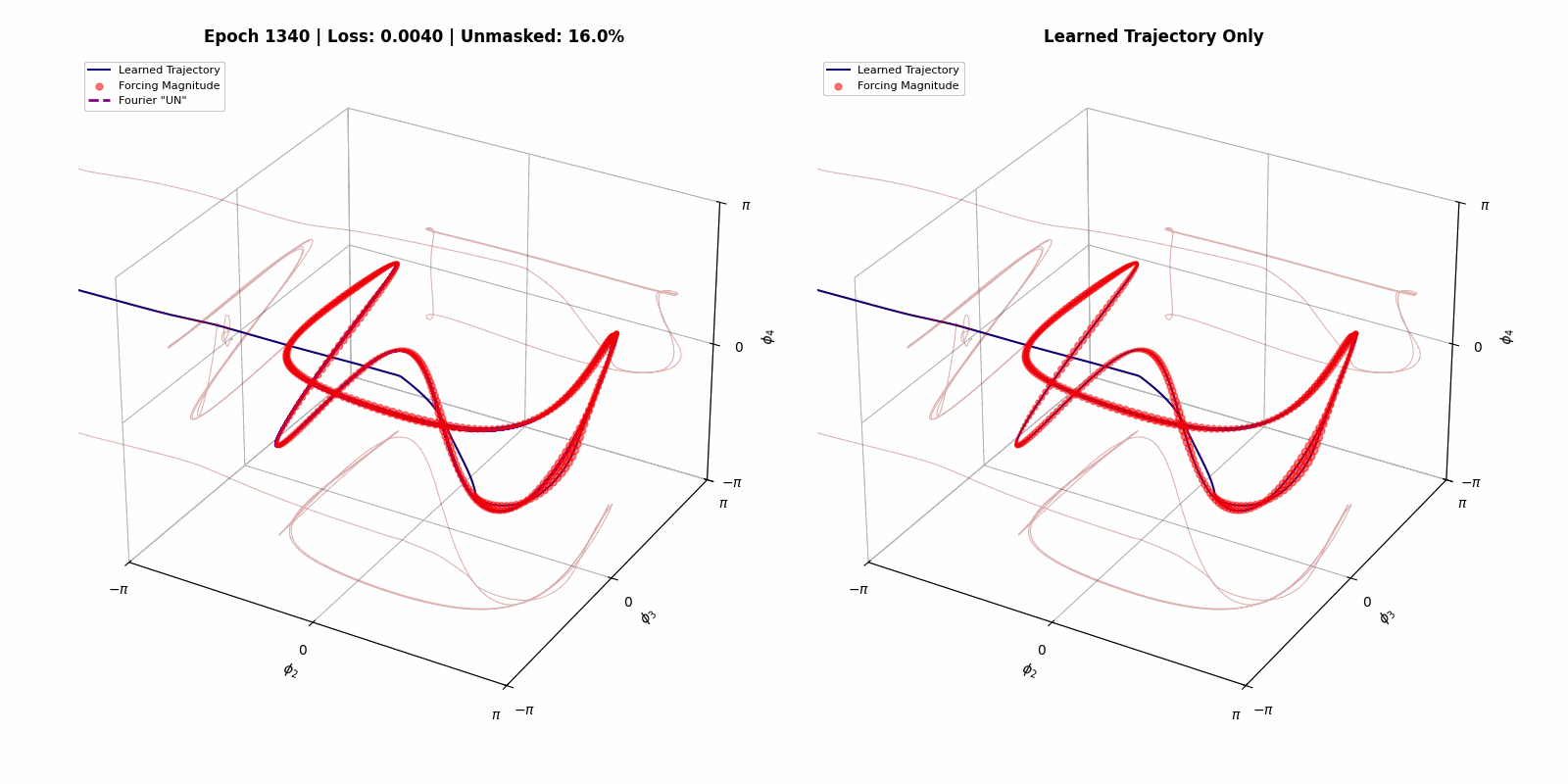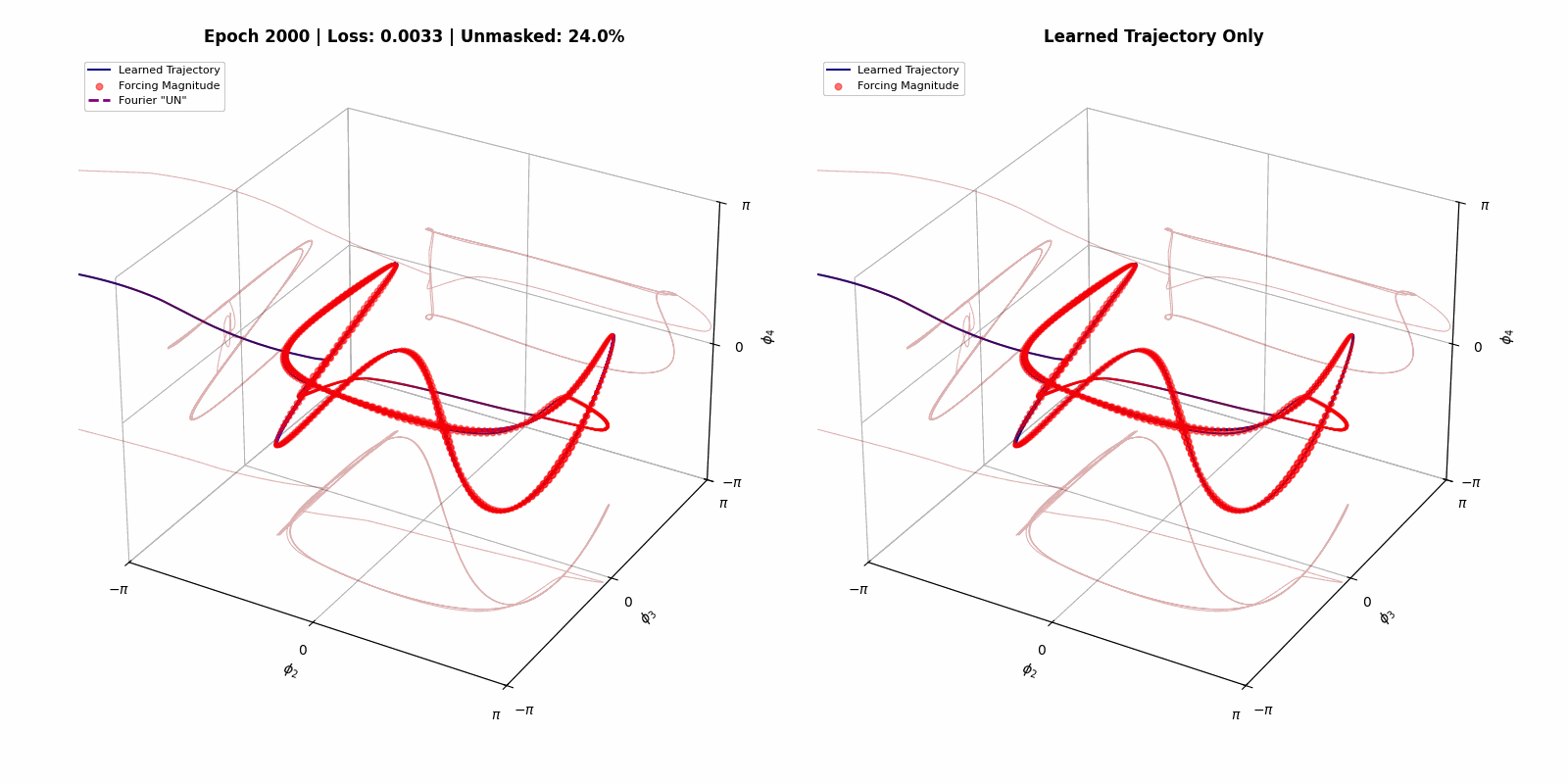
Here we show that we can build a steerable, trainable system out of a simulation of a physical dynamical system. The goal state space trajectory is on the left, and the trained system evolving in time is on the right (credit to Matthew Bull for the images).
Reframing AI to be powered by dynamical systems is the key to enabling innovation beyond conventional 2D electronics in the long term. This new foundation allows us to engineer systems that use 3D architectures, feature interesting time-varying dynamics, and are built from entirely new materials. For example, computation can be implemented through a simple bucket of water exhibiting a dynamical system. By building intelligence natively on the physical world, we can bypass the constraints inherent in abstract, planar digital computation. The physics of all physical systems includes time, but our existing computing primitives do not. Now it is time to change that.
Constant neural co-evolution is a strong moat
Solving for 1000x efficiency means tackling the entire system from day zero. Our moat is the ability to connect the entire stack, from the physical layer all the way up to AI systems. Establishing an organization that maintains a constant, top-to-bottom and bottom-to-top iterative loop ensures we continuously push the frontier of system efficiency, establishing a durable competitive advantage against siloed competitors.
In 2014, we saw the paradigm shift where the computer’s purpose changed from strict deterministic operation to becoming a substrate for intelligence. A decade later, the industry has delivered faster, larger machines, but largely by optimizing old abstractions. Now is the time to usher in a new era of “computing,” one that builds intelligence natively on the physical world.