May 7, 2026
Research
How to improve AI energy efficiency by 1000x
Written by:
Unconventional AI’s mission is to achieve a 1000x energy-efficiency advantage for generative AI (GenAI) inference over state-of-the-art AI models running on state-of-the-art conventional AI hardware, with a focus on datacenter use cases. The high-level approach we are taking is to develop both the AI models and the AI hardware from the ground up together – co-evolving their development so that the hardware operates as close to the limits of what is physically possible with current CMOS technology, and the AI models running on the hardware optimally match the hardware’s capabilities.
In this blog post, we are going to explain two main challenges to achieving a 1000x advantage and describe approaches at our disposal to pursue this goal in spite of these challenges. While both developing new AI models and developing new hardware are equally important, this blog post will focus on hardware considerations but will point out the opportunities for efficiency gains from the interaction of hardware design with AI model design.
What is the baseline?
The baseline we compare ourselves against is the end-to-end system energy cost to produce results of the same quality as those produced by state-of-the-art AI models running on state-of-the-art conventional hardware (such as GPUs or TPUs). The metrics we are optimizing for are Joules per token (for GenAI text) or Joules per image (for GenAI images), iso-quality with the existing solutions we are comparing against. We also consider latency and throughput requirements, as well as chip area and price, as secondary, but important, metrics.
We are not focusing on arithmetic metrics like TOPS (Tera Operations per Second) and TOPS/Watt – these are not what ultimately matter and too easily result in apples-to-oranges comparisons.
What is the current state-of-the-art in energy efficiency? There is a large spread of Joules-per-token and Joules-per-image values in the ML.ENERGY Leaderboard. The spread arises, in part, from the different quality of tokens and images that are produced (which in turn is controlled by model architecture, number of parameters, training methods, datasets, etc.). However, to give some representative numbers for energy efficiency, the largest models use ~10 Joules per token for text and >10,000 Joules per image for images.
The throughput that modern systems are capable of is ~1000 tokens per second per user (i.e., without batching), using an 8-GPU system with a maximum power consumption of ~14 kW.¹
We also need to aim for where the ball is going to be: the relevant baseline for us is not the 2026 state-of-the-art; it is what we anticipate will be possible using conventional approaches in ~2030.
Challenge #1: Data movement
The energy cost of inference is dominated not by the cost of computation (arithmetic calculations) but by the cost of data storage/access and movement. Horowitz articulated the importance of considering memory-access energy in hardware accelerators in 2014, emphasizing the orders-of-magnitude difference in the energy cost of arithmetic versus both on-chip and off-chip memory accesses. Updated numbers for CMOS (7 nm) in 2021 from Google show the same gap: a >500x difference in energy cost of 8-bit integer multiplications versus 8-bit operand reads from off-chip high-bandwidth memory (HBM).
However, the situation has gotten more severe since 2014 in a crucial way: the model sizes have grown from millions of parameters to >1T parameters, with >100B active parameters. This means the models are now so large that they cannot fit in the memory on a single chip. As a result, the memory access costs in a modern inference accelerator (e.g., a B200 GPU or TPU 8i) are often the biggest ones: for off-chip HBM rather than on-chip SRAM accesses.
The fact that models do not fit in on-chip memory presents a central challenge for improving energy efficiency. It is estimated that off-chip memory (HBM) consumes 20%+ of GPU power in current GenAI inference datacenters. Unless the off-chip memory energy cost can be reduced, it is not possible to achieve an improvement in energy efficiency greater than 10x (see Challenge #2 below).
It can be helpful to build intuition for the memory problem by performing some very coarse back-of-the-envelope calculations. Imagine you were doing inference on an AI model with 100 billion (10¹¹) active parameters. What is the Joules-per-token energy cost if…
- …you only count arithmetic, assuming one 8-bit integer multiplication per parameter? 100B * 0.07 pJ = 0.007 Joules per token.
- …you stored the whole AI model in SRAM and you only count SRAM reads of parameters? 100B * 2 pJ (per 8 bits) = 0.2 Joules per token.²
- …you stored the AI model in off-chip HBM and you only count HBM reads of parameters? 100B * 39 pJ (per 8 bits) = 3.9 Joules per token.³
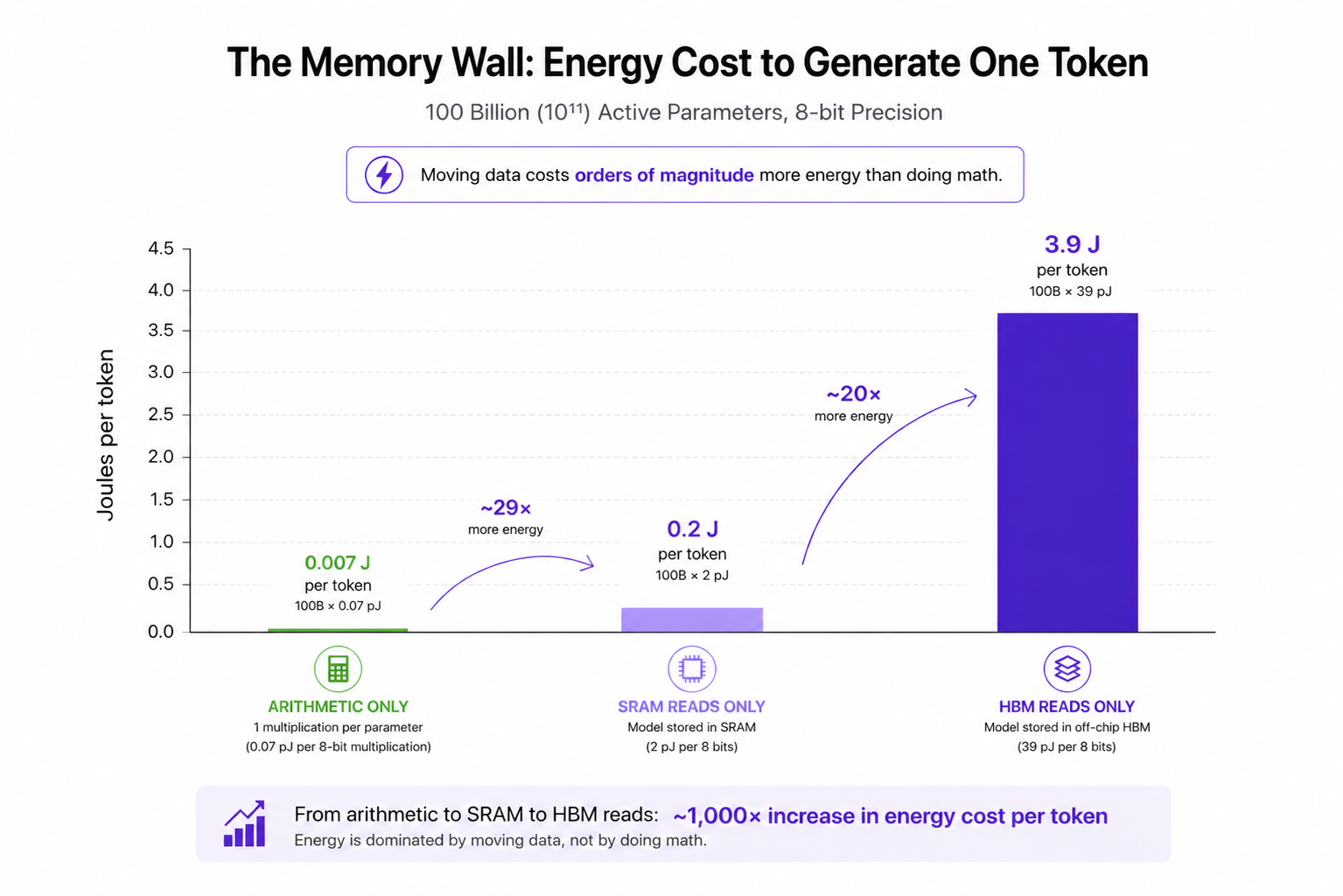
As we can see from these very coarse estimates, to get a 1000x win, you need to deal with memory somehow. Simply going from off-chip memory to on-chip memory isn’t sufficient: transitioning from off-chip HBM to on-chip SRAM provides at best a 10x advantage under unrealistically favorable conditions (the measured benefit in Joules per token for Transformer models is ~1.5x).
The above back-of-the-envelope calculations didn’t consider the key-value (KV) cache, which for long context lengths (e.g., 32k) can require reads of ~50 GBytes, i.e., comparable to the 100 GBytes we were assuming needed to be read for the model parameters. As a result, off-chip HBM reads of the KV cache may alone contribute ~2 Joules per token. For even longer context lengths (e.g., 1M), the KV cache could exceed 1 TByte, requiring many GPUs to even store it, and on the order of 100 Joules per token just to read the KV cache.
If we kept the energy cost of multiply-accumulate (MAC) arithmetic operations the same and eliminated all energy costs from memory, we would likely immediately get a ~1000x energy advantage. This is another way of seeing that getting a 1000x advantage is about memory and not about the efficiency of individual arithmetic operations.
Challenge #2: Amdahl’s Law
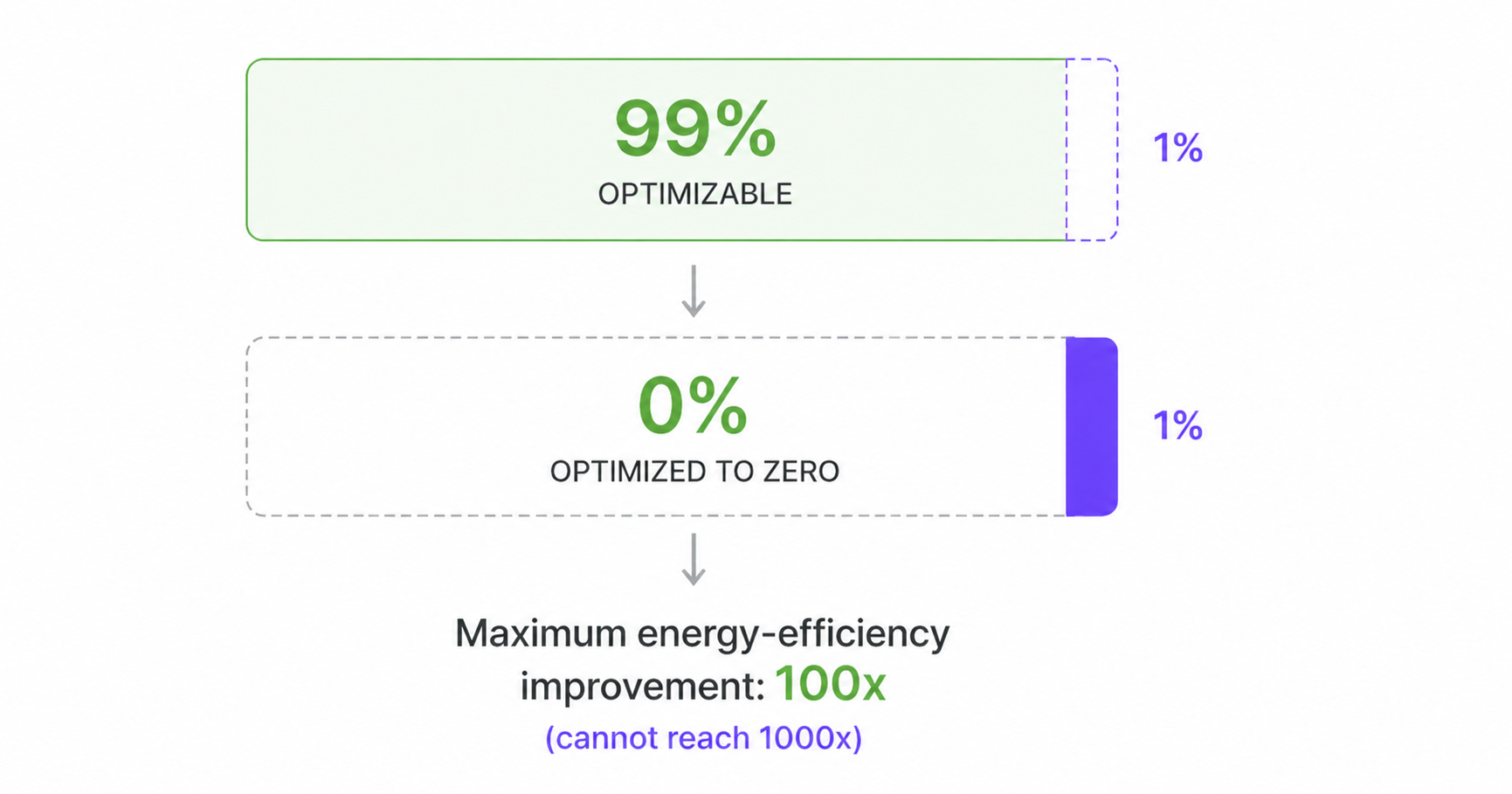
Amdahl’s Law, in the context of energy efficiency, states that the system-level improvement you can achieve by reducing the energy consumption of parts of the system is limited by what fraction of the energy budget those parts accounted for. This can present a major obstruction to achieving a 1000x improvement because it means that small contributions to the original energy cost can prevent you from achieving your goal, even if you make enormous improvements to most of the system.
For example, suppose you focus on improving the energy efficiency of the parts of a system that – before your optimization – are responsible for 99% of the system’s energy cost. If you optimize those parts, the largest system-level improvement you can achieve is only 100x, even if you manage to reduce the energy cost of the parts you are optimizing to zero.
The challenge presented by Amdahl’s Law appears repeatedly when reimagining hardware for AI inference. For example, you can’t meet the goal by tackling just the 99% core of energy usage, leaving the 1% of overhead tasks unoptimized. You certainly can’t tackle only the compute energy costs while ignoring the data energy costs. You also can’t target Transformer models and only eliminate the energy cost for the linear layers, but not for the Attention layers.
Our philosophical approach at Unconventional AI of concurrently designing both the hardware and the AI models that run on it from scratch helps us avoid “small” costs in running existing models that are hard to reduce the energy costs of, and might otherwise prevent a 1000x advantage.
What are the open problems that need to be solved?
Challenge #1 together with Challenge #2 implies: we must (1) reduce model sizes (e.g., by taking advantage of dynamics in the hardware, which effectively reuses parameters), and/or (2) reduce memory cost, and/or (3) minimize data movement (e.g., by keeping storage as local to computation as possible).
We need memory with high enough density that we can fit the entire model in on-chip memory or in 3D-integrated memory that is close to the chip. We need locality so that data stored in memory is used near the memory physically on the chip. Assuming 2.4 pJ per byte to transfer data between 2D-integrated chips, or across the full width of a single chip, data communication alone would cost >0.2 Joules per token for a 100B-parameter model. This is enough to prevent anything larger than a ~10x improvement in energy efficiency over the current state-of-the-art.
Challenge #2 implies that we have to optimize almost everything about the system to reach 1000x, and we can’t have any overhead beyond 0.1% of the original energy cost.
How to get to 1000x?
Here are some approaches at our disposal. Each of them can be taken to an extreme, or one can go only part of the way. For example: don’t fully specialize the hardware to the computation, but specialize more than a GPU currently does.
Specialization to a specific AI model architecture or class of model architectures: design the hardware architecture to match an AI model’s architecture so that the data movement is minimized. For example, dataflow architectures can be spatially laid out in CMOS to minimize the distance that neuron activations need to traverse to reach the next layer of the neural network, which in turn can reduce energy consumption.
Specialization to a specific AI model (hard-wired parameters): even more extreme than designing the AI hardware to map exactly to the AI model architecture one wishes to run on it, is to specialize to a specific trained instantiation of that model by hard-wiring the model parameters in the chip. This has been an approach adopted by Taalas and advocated for in academic papers.
Parameter efficiency: reduce the total amount of memory required by trading off using fewer parameters and more computation with those parameters. This has been explored in the conventional ML community in work on deep equilibrium models and recursive models. Physical dynamical systems realized in electronic circuits can naturally incorporate the lessons from these approaches, and, in some cases, it is even more natural to implement them with continuous-time physical systems.
Sparsity: sparse recurrent systems can achieve comparable accuracy to dense feedforward networks. An engineered electronic dynamical system’s power consumption can be lower if it is sparse.
Avoid Attention using dynamics: Attention, and the loading of the KV cache in inference, is a major bottleneck for GPU implementations of Transformers and would likely also be for any unconventional hardware accelerator that implements Attention. Architectures such as state-space models (Mamba) have shown that it is possible to achieve high token quality without Attention. Their methods and intuitions can be applied to unconventional hardware for realizing neural networks.
Allow non-mathematical-isomorphism to current NNs (aka CMOS circuits as realizations of physical neural networks): AI & neural networks don’t need exact matrix-vector multiplications; they need expressive parameterized input-output relations. Don’t force circuits to exactly realize matrix-vector multiplications. Instead, allow them to do what they most naturally do energy-efficiently. This philosophy applies to both analog and digital circuits; for example, others have explored coupled oscillators (analog) and trained lookup tables (digital) as neural networks.
What properties of CMOS circuits are desirable for them to be promising as a physical neural network?
- Expressive: can represent many complicated nonlinear functions.
- Many parameters: can have a lot of trainable parameters (programmable or hard-wired).
- Expensive to simulate: if a circuit requires less energy to simulate with a current digital processor than it does to run physically, then it is not a promising candidate. We want circuits that are like wind tunnels: cheaper to run physically than to simulate digitally.
- Trainable by gradient descent: we must be able to learn the parameters of the circuit that cause the circuit to have the behavior we want. If we want to use backpropagation running on a digital computer for training, the circuit needs to have a reasonably accurate behavioral model.
Use analog circuits: there are potential energy advantages to using analog circuits versus digital circuits for low-precision computing. We can use analog circuits where they give us a benefit and digital circuits elsewhere.
Tolerate noise: don’t over-engineer circuits to achieve too high of a signal-to-noise ratio, which usually costs energy. Neural networks can tolerate a certain amount of noise if the noise is considered during training.
Ultimately, to get to a 1000x energy-efficiency advantage, we may not rely on a single approach for the entire advantage. Instead, we may build up the 1000x advantage by engineering 10 factors of 2x, or 3 factors of 10x.
If you’re interested in helping us figure out how to do it, apply and join the pursuit!
¹ This gives another data point that is consistent with ~10 Joules per token.
² This is optimistic because it assumes the use of 1 MB (not larger) SRAMs and that you can use the result locally, i.e., without further energy cost for moving the data.
³ An important caveat here is that conventional (e.g., GPU) implementations attempt to amortize the cost of off-chip memory reads by reusing the values that are read from off-chip memory many times, for example by processing batches of queries rather than a single query at a time. The number calculated here is for the extreme case of no reuse of parameters loaded from off-chip memory.